经验误差与过拟合
- 目的 得到在新样本上表现很好的学习器
1. 训练 / 经验误差 training /empirical error
-
def 学习器在训练集上的误差
2. 泛化误差 generalization error
-
def 学习器在新样本上的误差
-
一般地,假设测试样本是从样本真是分布中独立同分布采样得到,则测试集的测试误差可视为泛化误差的近似
3. 欠拟合 / 过拟合 underfitting /overfitting
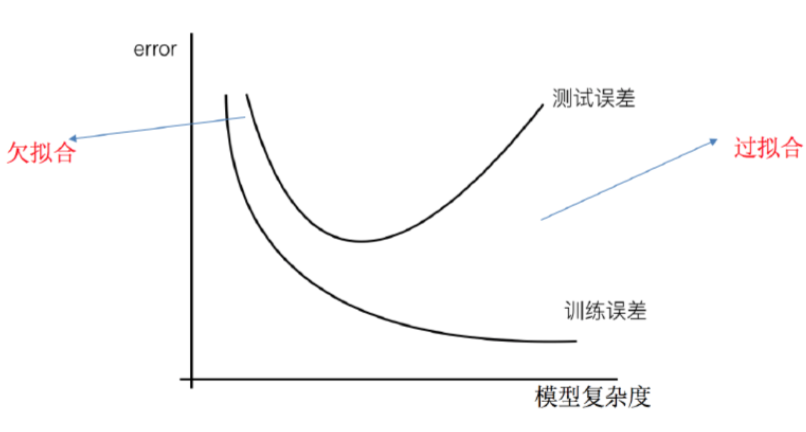
-
def 前者单纯训练得不够或学习能力低下,后者则已经把样本自身的某些特点当做所有样本都有的一般性质,使得泛化性能下降
-
解决 前者增加轮数, 后者无法彻底避免,仅可使得经验误差最小化以缓解其风险
评估方法
1. 留出法 hold-out
-
method 直接将数据集 D 划分为两互斥集合,分别作为训练集 S、测试集 T
-
quiz1 如何保持数据分布的一致性?
答:分层采样(stratified sampling),尽可能避免因数据划分引入额外的偏差而对最终结果产生影响
-
quiz2 给定 S/T 比例,如何划分?
答:单次结果并不稳定,可多次随机划分,每次产生一个训练 / 测试集结果并评估,最后留出法返回的结果是每次划分结果的平均值
-
quiz3 最佳比例?
答:2:1(67%) ~ 4:1(80%),训练集过大可能使得模型更接近用 D 训练出的模型,而评估结果则不够准确;若测试集过大,则 S 与 D 的差别过大,评估模型与用 D 训练出的模型有较大差别,降低了评估结果的保真性(fidelity)
2. 交叉验证法 cross validation(常用)
-
method 经分层采样,将 D 划分为 k 个大小相似的互斥子集,这样一来,每次课使用 k-1 个子集的并集作为训练集,余下的那个子集则作为测试集;得到 k 组结果,返回其均值
-
quiz1 常用 k?答:10,10 次十折交叉验证
-
quiz2 留一法有了解吗?
答:当 D 包含 m 样本,而 m 恰等于 k 时的特例。其好处在于不受随机样本划分方式的影响,且和 D 训练得到的模型会很相似;坏处在于模型训练的计算开销大,计算复杂度高
3. 自助法 bootstrapping
-
method 以自助采样(bootstrap sampling)为基础,给定包含 m 个样本的数据集 D,我们对它进行采样产生数据集 D’;每次随机从 D 中挑选一个样本,将其拷贝放入 D’,再将该样本放回初始数据集 D 中,使得该样本在下次采样时仍有可能被采到;这个过程重复执行 m 次后,得到包含 m 个样本的数据集 D’,是为自助采样的结果
-
application 数据集小、难以划分;改变了初始数据集的分布,从而引入了额外的估计误差
-
quiz1 样本在 m 次采样中始终不被采到的概率?
-
quiz2 划分?
答:D‘作为 S,D/D’作为 T,测试结果为包外估计(out-of-bag-estimate)
性能度量
1. 错误率 error rate
-
def 分类错误样本占样本总数的比例
-
m 个样本中有 a 个样本分类错误,则
2. 精度 accuracy
-
def 分类正确样本占样本总数的比例
-
m 个样本中有 a 个样本分类正确,精度 = 1 - 错误率
3. 混淆矩阵 confusion matrix
-
def 误差矩阵,表示精度评价的一种标准格式,为 n 行 n 列的矩阵形式
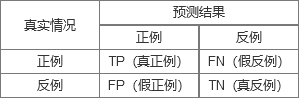
-
正例:positive,即最后结果是正向的(比如好瓜);
-
反例:negative,即最后结果是负向的(比如烂瓜);
-
TP:True Positive,把正例预测为正例,也就是说,首先预测出来是个正例,其次这是一个真正的正例(比如预测出来是个好瓜,而且是个好瓜);
-
FP:False Positive,把反例预测为正例,也就是说,首先预测出来是个正例,其次这是个反例(比如预测出来是个好瓜,但是是个烂瓜);
-
FN:False Negative,把正例预测为反例,也就是说,首先预测出来是个反例,其次这是个正例(比如预测出来是个烂瓜,但是是个好瓜);
-
TN:True Negative,把反例预测为反例,也就是说,首先预测出来是个反例,其次这是一个真正的反例(比如预测出来是个烂瓜,而且是个烂瓜)
4. 准确率 / 查准率 Precision
5. 召回率 / 查全率 Recall
6. P-R 图
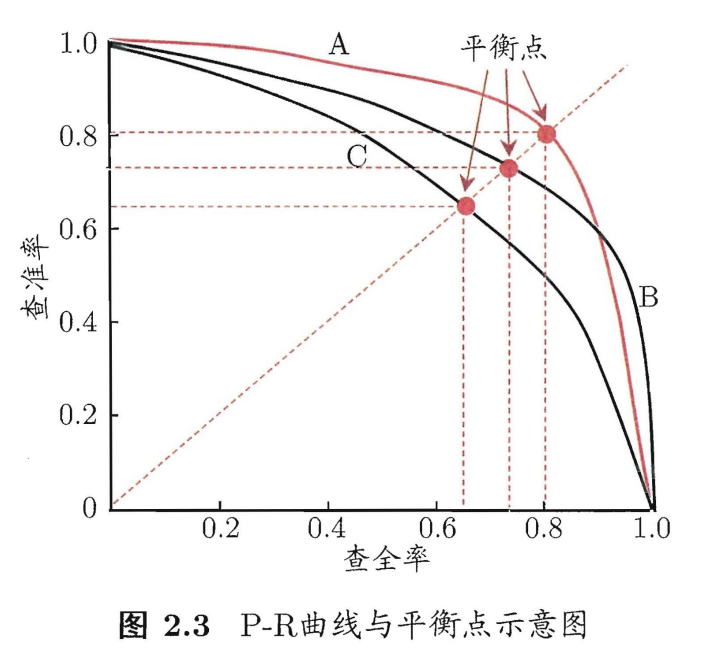
-
quiz 判断两个学习器的性能优劣?
答:若有两学习器 A、B,如果 B 的曲线被 A 完全包住,则可认为 A 的性能优于 B;若发生交叉,则只能:(1)在具体 P、R 条件下进行比较;(2)直接比较 A 和 B 对应 P-R 曲线的线下面积 Sa、Sb 的大小,较大者性能更优
7. 平衡点 Break-Event Point,BEP
-
def P = R 时的取值
8. F1 Score
-
def 基于查准率和查重率的调和平均(harmonic mean)