概述
定义
-
按照一定规则,自动抓取万维网信息的程序或脚本
分类
-
通用网络爬虫(General Purpose Web Crawler):根据一个种子 url 链接,扩展至整个 web 页面进行爬取,主要有深度优先爬行策略和广度优先爬行策略(见:数据结构与算法),应用于大型搜索引擎中
-
聚焦网络爬虫(Focused Crawler):有目的性地进行爬取,将爬取目标定位在与主题相关的页面中,主要有基于内容评价、基于链接评价、基于增强学习、语境图和关于聚焦网络爬虫具体的爬行策略,主要应用在对特定信息的爬取中
-
增量式网络爬虫(Incremental Web Crawler):是指对已下载网页采取增量式更新和只爬行新产生的或者已经发生变化网页的爬虫,在更新的时候只更新改变的地方,而未改变的地方则不更新。它能够在一定程度上保证所爬行的页面是尽可能新的页面深度网络爬虫
-
深层网络爬虫(Deep Web Crawler):需要提交表单信息的,或者需要传递一些关键词才可以访问这个数据。最重要的部分即为表单填写部分,主要有基于领域知识的表单填写与基于网页结构分析的表单填写两种类型
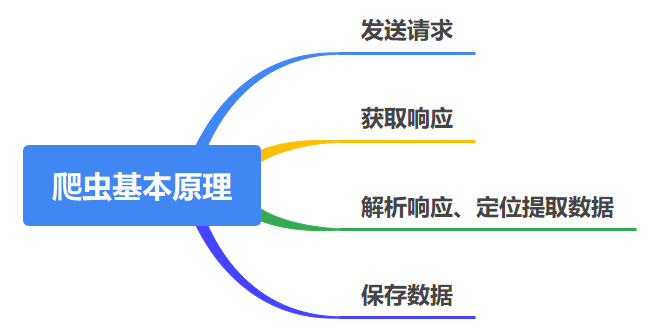
原理
数据
数据的分类
-
用广产生的数据,微信数据、抖音
-
政府的数据
-
公司管理的数据:聚合
-
自己爬取的数据
数据的用途
-
人工智能、机器学习、数据分析 etc.
robots 协议
-
网站和爬虫协商的协议,网站中某些站点不允许爬虫的访问
反爬取措施
-
验证码
- 手机验证码
- 静态(图片验证、文字)/ 动态(苹果动态验证)
-
ip 检测与封禁
-
文字混淆、js 加密
-
点击验证、滑块验证、滑动轨迹
-
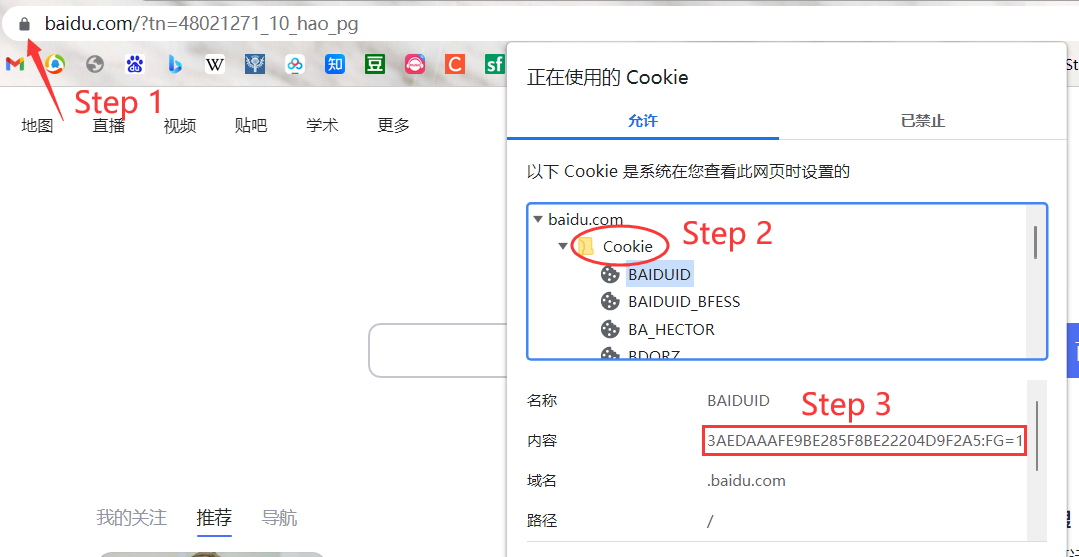
cookie:身份校验
-
防盗链 referer host
URL 的组成
-
统一资源定位符:https://baike.baidu.com
-
协议:https
-
域名:baike.baidu. com
-
端口:443
-
查询路径:/item/url
-
查询参数:wd=url
-
锚点
- 网页中,当前页面进行锚点定位
- 作用在网址的导航
静态数据和动态数据
-
静态数据:爬取的数据,在 html 源码中,并且这个页面是个静态页面
-
动态数据:通过一定条件触发的、二次加载的数据
Chrome 调试
-
User-Agent:身份标识
cookie&session